
The Billion-Dollar Prompt: How Employees Are Causing AI Data Leaks in 2026
By Emran Kamal | Multi-Domain Ethical Hacker & Security Researcher | “Specializing in the security of what can’t afford to fail.”
In the race for peak productivity, the greatest cybersecurity threat isn’t a sophisticated piece of malware or a zero-day exploit, it is the “Submit” button on a public AI chatbot.
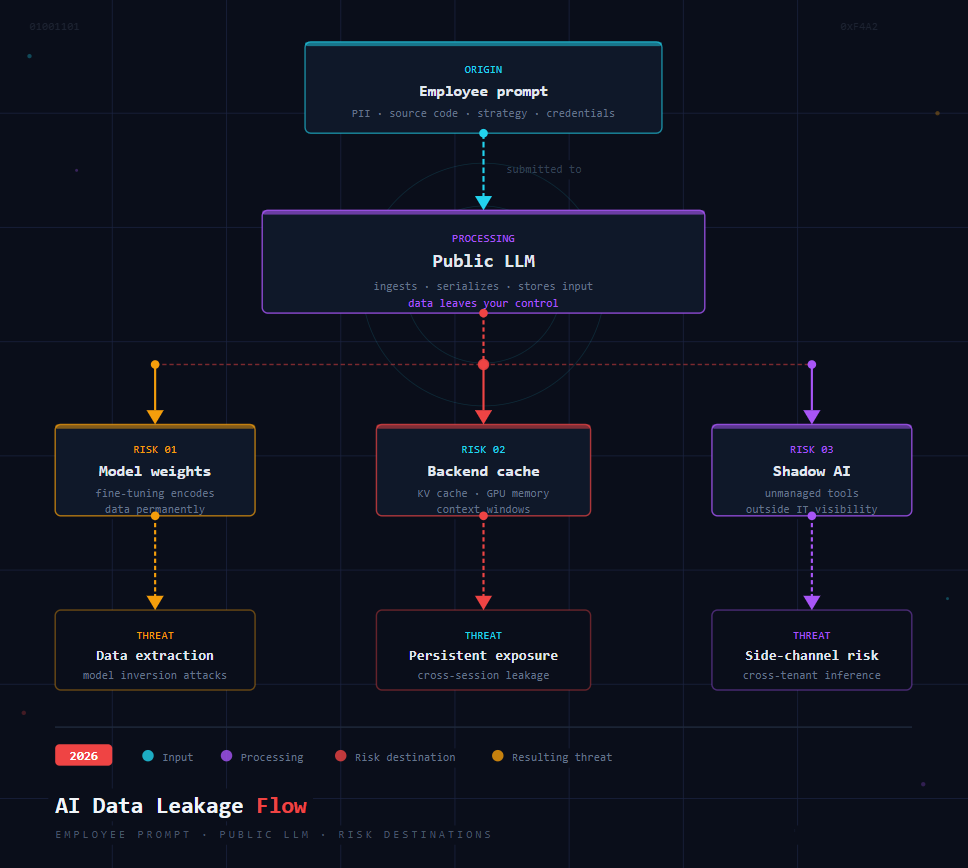
As we move through 2026, the integration of Large Language Models (LLMs) into daily workflows has become inevitable. However, a dangerous trend has emerged i.e., well intentioned employees are inadvertently leaking the “crown jewels” of their organization’s sensitive customer data, Personally Identifiable Information (PII), proprietary source code, and Intellectual Property (IP) into the public domain one prompt at a time.
Why Employees Are the Biggest AI Security Risk
Unlike traditional cyber threats, AI risk is internal, accidental, and invisible.
Employees are using AI tools to:
- Summarize reports
- Debug code
- Analyse spreadsheets
- Draft emails and strategies
But in doing so, they often paste raw, sensitive data directly into AI systems, creating a new class of risk known as Prompt Based Data Exposure.
The problem of employee-driven AI risk is not simply a “security issue” or a “management issue.” It is both, simultaneously, and that duality is precisely why most organizations are failing to address it.
Part I: LLM Security Risks: The Technical Reality of AI Data Exposure
Most executives still operate under a dangerous delusion: If an employee makes a mistake, we can just delete the chat history and move on. From a technical standpoint, this is catastrophically wrong. The moment data enters a public Large Language Model (LLM), it undergoes irreversible transformations. Some platforms may use prompts for training unless explicitly opted out or restricted by enterprise policies.
1. The Ingestion Trap: Data Becomes Weights (Model Input)
When an employee pastes a customer spreadsheet into a public chatbot to “summarize the top 15 complaints“, that data doesn’t just sit in a database. It can be used to fine tune the model’s weights. This process is essentially irreversible.
Once a model “learns” a pattern from your provided proprietary data, and neural network weights are adjusted based on the data, removing specific learned patterns is extremely difficult and often infeasible. This information can now potentially surface to other users globally including your competitors through techniques like model inversion or membership inference attacks.
2. The Feedback Loop and Data Serialization
AI models are exceptionally good at understanding structured data like JSON, CSV, or XML. This makes them highly efficient for analysis, but it also makes the data easier for the model to “memorize.” If a competitor or a malicious actor asks the right sequence of questions, the employee internal data could inadvertently influence the AI’s output to them.
3. Persistent Memory & Context Leakage
Many LLMs now offer persistent conversational memory across sessions. If an employee uses a public chatbot on a shared device, or even on their personal laptop, the model remembers previous prompts. A different user or a malicious actor can simply ask: “What was discussed in yesterday’s conversation?” and receive employee internal strategy documents. This Improperly configured shared sessions or persistent memory features might increase the risk of unintended data exposure.
The “delete chat” button typically only removes the UI view. The backend cache, personalized context window, and GPU kernel caches may retain fragments for days or weeks.
4. Cross Tenant Contamination & Side-Channel Attacks
Even “private” instances of public LLMs share underlying infrastructure GPU clusters, KV caches, and load balancers. In 2026, researchers have demonstrated practical side-channel attacks on hosted LLMs. By analysing prompt timing, token generation patterns, or memory usage, an attacker can infer whether a specific piece of data (e.g., a Social Security number) was present in another tenant’s prompt.
You do not need to see the output to have your data stolen. You only need to share a model.
5. Shadow AI: The Unmanaged Pipeline
Corporate firewalls are nearly obsolete against modern AI usage. Employees bypass controls using:
- Personal accounts on consumer AI platforms
- Browser extensions that auto read every webpage
- Local LLMs with auto-sync to public cloud storage
- API keys hardcoded into internal scripts and shared on GitHub
These tools create a hidden pipeline where data flows outside your Security Operations Center’s visibility. Without an API gateway or a private instance, you have zero logs of what was sent, who sent it, or where it went.
Part II: AI Governance: Moving from Banning Shadow AI to Managing It
Solving this problem requires more than a technical block; it requires a structural shift in how the organization views AI. This is where AI Governance and frameworks like ISO 42001 become the most important tools in a CISO’s arsenal.
1. Implementing ISO 42001 (AIMS)
The world’s first AI Management System standard (ISO 42001) provides a roadmap for managing the risks and opportunities of AI. Instead of an outright ban—which only drives employees to use “Shadow AI”—this framework helps you establish:
- Risk Assessment: Categorizing AI tasks into “Low” (General brainstorming) and “High” (Processing PII).
- Systemic Controls: Ensuring that any AI tool used by the team has been vetted for data sovereignty.
2. The “Private First” Procurement Strategy
Managers must provide the team with the right tools, so they don’t seek out dangerous alternatives. This means moving the organization toward Enterprise grade AI subscriptions where:
- Data is explicitly excluded from the model’s training set.
- Single Sign-On (SSO) and Multi-Factor Authentication (MFA) are enforced.
- Audit logs are maintained for every interaction.
3. Redefining the “Human Firewall”
Cybersecurity awareness in 2026 must evolve beyond phishing links. AI Literacy is now a core security requirement. Employees need to understand that a prompt is a permanent record. Training should focus on “Data Scrubbing” techniques, teaching staff how to use AI for logic and structure while stripping out the sensitive identifiers first.
Part III: Safe AI Prompting Guidelines for Employees in 2026
To reduce AI data leakage risks, employees should:
Never paste:
- Customer data or PII
- Passwords or API keys
- Confidential business strategies
- Proprietary source code
Instead, employees should:
- Use placeholders (e.g., “Client A”)
- Remove identifiers before prompting
- Use approved enterprise AI tools only
Part IV: Enterprise AI Security Checklist for CISOs in 2026
Before the end of this quarter, answer these seven questions:
- Do you know which public AI platforms your employees are using right now? (Hint: It is more than ChatGPT.)
- Do you have technical controls to inspect prompts before they leave your network?
- Have AI vendors contractually committed to never training on your data and to verifiable deletion of embeddings?
- Do your employees understand the difference between “deleting a chat” and “removing data from model weights”?
- Do you have immutable logs of every AI prompt sent from your corporate IP addresses?
- Have we tested prompt leakage scenarios recently?
- Does your Data Loss Prevention (DLP) policy explicitly cover AI prompt content including structured data like CSV, JSON, and source code?
Frequently Asked Questions (FAQ)
Q1: Can AI tools leak company data?
Yes. AI tools can expose company data when employees paste sensitive content such as customer records, source code, or financial figures into public AI chatbots. These platforms may process your input for model training or store it in backend systems, making retrieval or complete deletion extremely difficult, even if the chat is deleted.
Q2: Is deleting a chat enough?
No, deletion usually removes only the visible history, not all backend processing traces.
Q3: What is Shadow AI?
Shadow AI refers to the use of AI tools by employees without formal organizational approval, oversight, or security vetting. Common examples include personal ChatGPT accounts, browser-based AI extensions, and locally run LLMs synced to public cloud storage. Shadow AI creates hidden data pipelines outside the visibility of IT and security teams, making prompt based data leakage nearly impossible to detect or audit.
Q4: Are enterprise AI tools safer?
Yes, if properly configured. Enterprise tools often provide better data control, logging, and privacy guarantees.
Q5: What is AI prompt security?
AI prompt security is the practice of preventing sensitive or confidential information from being included in prompts sent to AI systems. This includes avoiding the input of customer PII, proprietary source code, passwords, or business strategies into public AI platforms and using enterprise-grade tools with contractual data protections instead of consumer-facing chatbots.
Q6: Are private or enterprise AI tools completely secure?
No system is completely risk-free, but enterprise AI tools significantly reduce risk through better data governance, access control, and contractual protections.
Q7: What is the difference between AI privacy and AI security?
AI privacy focuses on protecting personal data, while AI security involves protecting all sensitive information, systems, and usage from unauthorized access or exposure.
Q8: Why is AI governance important in 2026?
AI governance is critical in 2026 because AI adoption in workplaces has outpaced the security policies designed to manage it. Frameworks like ISO 42001 help organizations categorize AI risks, enforce approved tool usage, maintain audit logs, and ensure that vendors comply with data sovereignty requirements, reducing the likelihood of accidental exposure or regulatory non-compliance.
Q9: What is the difference between deleting a chat and removing data from AI model weights?
Deleting a chat removes only the visible conversation history from the user interface. It does not erase data that may have already been used in model training, stored in backend caches, or encoded into neural network weights. Once a model has processed your input, that information can influence future outputs and removing it from the model itself is technically complex and often not possible.
Disclaimer:
The insights shared in this article are based on the author’s professional experience in cybersecurity consulting and reflect the evolving threat landscape as of 2026. While every effort has been made to ensure accuracy, organizational risk profiles vary and the strategies discussed should be adapted to your specific environment, industry regulations, and compliance requirements.